Quick revision for RDBMS using MySQL - VIKATU
What is MySQL?
- MySQL is a relational database management system
- MySQL is open-source
- MySQL is free
- MySQL is ideal for both small and large applications
- MySQL is very fast, reliable, scalable, and easy to use
- MySQL is cross-platform
- MySQL is compliant with the ANSI SQL standard
- MySQL was first released in 1995
- MySQL is developed, distributed, and supported by Oracle Corporation
- MySQL is named after co-founder Monty Widenius's daughter: My
Start MySQL Server on Linux
To start MySQL Server on Linux, you follow these steps:
First, open the Terminal program.
Second, run the following command to start the MySQL service:
sudo systemctl start mysqlIn this command, you need to replace the “mysql” with the actual service name if the MySQL service is different.
Third, check the status and confirm that the service has started successfully, you run the following command:
sudo systemctl status mysqlIf the MySQL service has started successfully, you should see “Active: active (running)“.
Mysql basic queries:
create database db1;
It manages and modifies the data in the database.
- Select: Select keyword in MySQL is used to retrieve data from a table.
- Insert: Insert or add data into a table.
- Update: Update the existing data in a table.
- Delete: Delete all records from a database table.
- Merge: It is a kind of insert or update operation.
- Call: Call statement calls a PL/SQL or any subprogram.
- Explain plan: Interpretation of the data access path.
- lock table: Concurrency Control
DDL Commands in SQL
DDL is an abbreviation of Data Definition Language.
The DDL Commands in Structured Query Language are used to create and modify the schema of the database and its objects. The syntax of DDL commands is predefined for describing the data. The commands of Data Definition Language deal with how the data should exist in the database.
Following are the five DDL commands in SQL:
- CREATE Command
- DROP Command
- ALTER Command
- TRUNCATE Command
- RENAME Command
CREATE Command
CREATE is a DDL command used to create databases, tables, triggers and other database objects.
Examples of CREATE Command in SQL
Example 1: This example describes how to create a new database using the CREATE DDL command.
Syntax to Create a Database:
CREATE database database_name;
DROP Command
DROP is a DDL command used to delete/remove the database objects from the SQL database. We can easily remove the entire table, view, or index from the database using this DDL command.
ALTER Command
ALTER is a DDL command which changes or modifies the existing structure of the database, and it also changes the schema of database objects.
We can also add and drop constraints of the table using the ALTER command.
TRUNCATE Command
TRUNCATE is another DDL command which deletes or removes all the records from the table.
This command also removes the space allocated for storing the table records.
RENAME Command
RENAME is a DDL command which is used to change the name of the database table.
RENAME TABLE Old_Table_Name TO New_Table_Name;
TCL Commands in SQL
- In SQL, TCL stands for Transaction control language.
- A single unit of work in a database is formed after the consecutive execution of commands is known as a transaction.
- There are certain commands present in SQL known as TCL commands that help the user manage the transactions that take place in a database.
- COMMIT. ROLLBACK and SAVEPOINT are the most commonly used TCL commands in SQL.
Now let us take a deeper dive into the TCL commands of SQL with the help of examples. All the queries in the examples will be written using the MySQL database.
1. COMMIT
COMMIT command in SQL is used to save all the transaction-related changes permanently to the disk. Whenever DDL commands such as INSERT, UPDATE and DELETE are used, the changes made by these commands are permanent only after closing the current session. So before closing the session, one can easily roll back the changes made by the DDL commands. Hence, if we want the changes to be saved permanently to the disk without closing the session, we will use the commit command.
COMMIT;
TCL Commands in SQL
- In SQL, TCL stands for Transaction control language.
- A single unit of work in a database is formed after the consecutive execution of commands is known as a transaction.
- There are certain commands present in SQL known as TCL commands that help the user manage the transactions that take place in a database.
- COMMIT. ROLLBACK and SAVEPOINT are the most commonly used TCL commands in SQL.
Now let us take a deeper dive into the TCL commands of SQL with the help of examples. All the queries in the examples will be written using the MySQL database.
1. COMMIT
COMMIT command in SQL is used to save all the transaction-related changes permanently to the disk. Whenever DDL commands such as INSERT, UPDATE and DELETE are used, the changes made by these commands are permanent only after closing the current session. So before closing the session, one can easily roll back the changes made by the DDL commands. Hence, if we want the changes to be saved permanently to the disk without closing the session, we will use the commit command.
2. SAVEPOINT
We can divide the database operations into parts. For example, we can consider all the insert related queries that we will execute consecutively as one part of the transaction and the delete command as the other part of the transaction. Using the SAVEPOINT command in SQL, we can save these different parts of the same transaction using different names. For example, we can save all the insert related queries with the savepoint named INS. To save all the insert related queries in one savepoint, we have to execute the SAVEPOINT query followed by the savepoint name after finishing the insert command execution.
3. ROLLBACK
While carrying a transaction, we must create savepoints to save different parts of the transaction. According to the user's changing requirements, he/she can roll back the transaction to different savepoints. Consider a scenario: We have initiated a transaction followed by the table creation and record insertion into the table. After inserting records, we have created a savepoint INS. Then we executed a delete query, but later we thought that mistakenly we had removed the useful record. Therefore in such situations, we have an option of rolling back our transaction. In this case, we have to roll back our transaction using the ROLLBACK command to the savepoint INS, which we have created before executing the DELETE query.
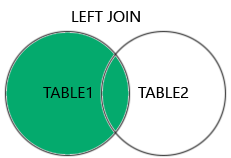
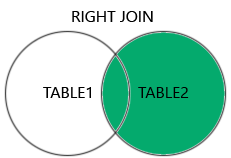
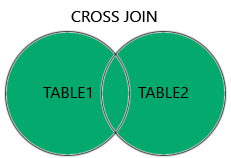
Supported Types of Joins in MySQL
INNER JOIN: Returns records that have matching values in both tablesLEFT JOIN: Returns all records from the left table, and the matched records from the right tableRIGHT JOIN: Returns all records from the right table, and the matched records from the left tableCROSS JOIN: Returns all records from both tables

SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
The SQL UNION Operator
The UNION operator is used to combine the result-set of two or more SELECT statements.
- Every
SELECTstatement withinUNIONmust have the same number of columns - The columns must also have similar data types
- The columns in every
SELECTstatement must also be in the same order
The MySQL Log Files
MySQL has several different log files that can help you find out what’s going on inside mysqld:
Log file | Description |
|---|---|
The error log | Problems encountered when starting, running, or stopping mysqld. |
The isam log | Logs all changes to the ISAM tables. Used only for debugging the isam code. |
The query log | Established connections and executed queries. |
The update log | Deprecated: stores all statements that change data. |
The binary log | Stores all statements that change something. Used also for replication. |
The slow log | Stores all queries that took more than long_query_time to execute or didn’t use indexes. |
All logs can be found in the mysqld data directory. You can force mysqld to reopen the log files (or in some cases switch to a new log) by executing FLUSH LOGS. See Section 4.5.3.
mysqld writes all errors to the stderr, which the safe_mysqld script redirects to a file called 'hostname'.err. (On Windows, mysqld writes this directly to \mysql\data\mysql.err.)
This contains information indicating when mysqld was started and stopped and also any critical errors found when running. If mysqld dies unexpectedly and safe_mysqld needs to restart mysqld, safe_mysqld will write a restarted mysqld row in this file. This log also holds a warning if mysqld notices a table that needs to be automatically checked or repaired.
On some operating systems, the error log will contain a stack trace that can be used to find out where mysqld died. See Section D.1.4.
If you want to know what happens within mysqld, you should start it with --log[=file]. This will log all connections and queries to the log file (by default named 'hostname'.log). This log can be very useful when you suspect an error in a client and want to know exactly what mysqld thought the client sent to it.
By default, the mysql.server script starts the MySQL server with the -l option. If you need better performance when you start using MySQL in a production environment, you can remove the -l option from mysql.server or change it to --log-bin.
The entries in this log are written as mysqld receives the questions. This may be different from the order in which the statements are executed. This is in contrast to the update log and the binary log which are written after the query is executed, but before any locks are released.
Note: the update log is replaced by the binary log. See Section 4.9.4. With this you can do anything that you can do with the update log.
When started with the --log-update[=file_name] option, mysqld writes a log file containing all SQL commands that update data. If no filename is given, it defaults to the name of the host machine. If a filename is given, but it doesn’t contain a path, the file is written in the data directory. If file_name doesn’t have an extension, mysqld will create log file names like so: file_name.###, where ### is a number that is incremented each time you execute mysqladmin refresh, execute mysqladmin flush-logs, execute the FLUSH LOGS statement, or restart the server.
Note: For the previous scheme to work, you must not create your own files with the same filename as the update log + some extensions that may be regarded as a number, in the directory used by the update log!
If you use the --log or -l options, mysqld writes a general log with a filename of hostname.log. Restarts and refreshes do not cause a new log file to be generated (although it is closed and reopened). In this case you can copy it (on Unix) by doing:
Update logging is smart because it logs only statements that really update data. So an UPDATE or a DELETE with a WHERE that finds no rows is not written to the log. It even skips UPDATE statements that set a column to the value it already has.
The update logging is done immediately after a query completes but before any locks are released or any commit is done. This ensures that the log will be logged in the execution order.
If you want to update a database from update log files, you could do the following (assuming your update logs have names of the form file_name.###):
ls is used to get all the log files in the right order.
This can be useful if you have to revert to backup files after a crash and you want to redo the updates that occurred between the time of the backup and the crash.
The intention is that the binary log should replace the update log, so we recommend you switch to this log format as soon as possible!
The binary log contains all information that is available in the update log in a more efficient format. It also contains information about how long every query that updated the database took.
The binary log is also used when you are replicating a slave from a master. See Section 4.10.
When started with the --log-bin[=file_name] option, mysqld writes a log file containing all SQL commands that update data. If no filename is given, it defaults to the name of the host machine followed by -bin. If a filename is given, but it doesn’t contain a path, the file is written in the data directory.
If you supply an extension to --log-bin=filename.extension, the extension will be silently removed.
To the binary log filename, mysqld will append an extension that is a number that is incremented each time you execute mysqladmin refresh, execute mysqladmin flush-logs, execute the FLUSH LOGS statement, or restart the server. A new binary log will also automatically be created when it reaches max_bin_log_size. You can delete all inactive binary log files with the RESET MASTER command. See Section 4.5.4.
You can use the following options to mysqld to affect what is logged to the binary log:
Option | Description |
|---|---|
binlog-do-db=database_name | Tells the master it should log updates for the specified database, and exclude all others not explicitly mentioned. (Example: binlog-do-db=some_database.) |
binlog-ignore-db=database_name | Tells the master that updates to the given database should not be logged to the binary log. (Example: binlog-ignore-db=some_database.) |
To determine which different binary log files have been used, mysqld will also create a binary log index file that contains the name of all used binary log files. By default this has the same name as the binary log file, with the extension '.index'. You can change the name of the binary log index file with the --log-bin-index=[filename] option.
If you are using replication, you should not delete old binary log files until you are sure that no slave will ever need to use them. One way to do this is to do mysqladmin flush-logs once a day and then remove any logs that are more than 3 days old.
You can examine the binary log file with the mysqlbinlog command. For example, you can update a MySQL server from the binary log as follows:
You can also use the mysqlbinlog program to read the binary log directly from a remote MySQL server!
mysqlbinlog --help will give you more information on how to use this program!
If you are using BEGIN [WORK] or SET AUTOCOMMIT=0, you must use the MySQL binary log for backups instead of the old update log.
The binary logging is done immediately after a query completes but before any locks are released or any commit is done. This ensures that the log will be logged in the execution order.
All updates (UPDATE, DELETE, or INSERT) that change a transactional table (like BDB tables) are cached until a COMMIT. Any updates to a non-transactional table are stored in the binary log at once. Every thread will, on start, allocate a buffer of binlog_cache_size to buffer queries. If a query is bigger than this, the thread will open a temporary file to handle the bigger cache. The temporary file will be deleted when the thread ends.
The max_binlog_cache_size can be used to restrict the total size used to cache a multi-transaction query.
If you are using the update or binary log, concurrent inserts will not work together with CREATE ... INSERT and INSERT ... SELECT. This is to ensure that you can re-create an exact copy of your tables by applying the log on a backup.
When started with the --log-slow-queries[=file_name] option, mysqld writes a log file containing all SQL commands that took more than long_query_time to execute. The time to get the initial table locks is not counted as execution time.
The slow query log is logged after the query is executed and after all locks have been released. This may be different from the order in which the statements are executed.
If no filename is given, it defaults to the name of the host machine suffixed with -slow.log. If a filename is given, but doesn’t contain a path, the file is written in the data directory.
The slow query log can be used to find queries that take a long time to execute and are thus candidates for optimisation. With a large log, that can become a difficult task. You can pipe the slow query log through the mysqldumpslow command to get a summary of the queries that appear in the log.
If you are using --log-long-format, queries that are not using indexes are also printed. See Section 4.1.1.
MySQL has a lot of log files, which makes it easy to see what is going on. See Section 4.9. One must, however, from time to time clean up after MySQL to ensure that the logs don’t take up too much disk space.
When using MySQL with log files, you will, from time to time, want to remove/back up old log files and tell MySQL to start logging on new files. See Section 4.4.1.
On a Linux (RedHat) installation, you can use the mysql-log-rotate script for this. If you installed MySQL from an RPM distribution, the script should have been installed automatically. Note that you should be careful with this if you are using the log for replication!
On other systems you must install a short script yourself that you start from cron to handle log files.
You can force MySQL to start using new log files by using mysqladmin flush-logs or by using the SQL command FLUSH LOGS. If you are using MySQL Version 3.21 you must use mysqladmin refresh.
The preceding command does the following:
If standard logging (--log) or slow query logging (--log-slow-queries) is used, it closes and reopens the log file (
mysql.logand`hostname`-slow.logas default).If update logging (--log-update) is used, it closes the update log and opens a new log file with a higher sequence number.
If you are using only an update log, you only have to flush the logs and then move away the old update log files to a backup. If you are using normal logging, you can do something like:
and then take a backup and remove mysql.old.
UNIT 2
What is MYSQL architecture?
MYSQL is a relational database with a layered kind of architecture. The layers of the architecture include a server resource end at the middle, the storage engine at the bottom, and the client-end or query execution end at the top. It’s a three-layered architecture database system.
The architecture of the database explains the relationship and interaction between the client-end, server-end, and storage-end of the system. Below are the various layers of the database system.

Client-end
The client-end of the MYSQL architecture is the part being interacted with by end-users of the database system. The user makes use of the graphic user interface screen or the command prompt for submission of various MYSQL commands to the server end.
For every valid command submission, there is a valid output on the screen; for every wrong command submission, there is an error message sent as feedback to the screen. When a user sends a request to the server-end and the server accepts the request, a connection is established at once to enable the user carry out further requests. This could be termed connection handling, and it’s a function rendered by the client-side of the architecture.
Server-end
The server-end of the architecture comprises the logic of the database system. It is the brain of the MYSQL architecture. It receives every request sent by the client-side and also returns feedback upon processing every request.
For every request sent by the client, there is an establishment of a connection, this connection is known as a thread on the server-side. The server end of the architecture helps in managing every established thread and this is known as thread handling. Thread handling is a function carried out by the server-end of the architecture.
Storage-end
The MYSQL database contains a different kind of storage engines which exist as a result of varying needs of databases. The storage engines are used to hold every user-created table in the database system. The storage-end facilitates the storing and retrieving of MYSQL data. The storage engine has an API that aids in the execution of the queries from the client end of the architecture just by passing rows back and forth in it.
There are 7 client programs, which are listed below −
mysql
mysqladmin
mysqlcheck
mysqldump
mysqlimportmysqlpump
mysqlshow
mysqlslap
Let us understand the MySQL client programs in brief −
mysql
The mysql is a simple SQL shell that has input line editing capabilities. It supports interactive and noninteractive usage. When it is used interactively, query results are presented in an ASCII-table format.
It can be invoked from the prompt of the user’s command interpreter. It has been demonstrated below −
shell> mysql db_name
mysqladmin
The mysqladmin is a client that helps perform administrative operations. It can also be used to check the server's configuration and current status, to create and drop databases, and much more.
mysqlcheck
The mysqlcheck client performs table maintenance. It checks, repairs, optimizes, or analyses tables.
Every table is locked and hence unavailable to other sessions when it is being processed. But for check operations, the table is locked with a READ lock only.
mysqldump
The mysqldump client utility helps performs logical backups, thereby producing a set of SQL statements which can be executed to reproduce the original database object definitions and table data. It dumps one or more MySQL databases for backup or transfer to another SQL server.
The mysqldump command also generates output in CSV, other delimited text, or XML format. The utility mysqldump requires at least the SELECT privilege for dumped tables, SHOW VIEW for dumped views, TRIGGER for dumped triggers, LOCK TABLES if the --single-transaction option is not used, and PROCESS if --no-tablespaces option is not used.
mysqlimport
The mysqlimport client comes with a command-line interface that helps with the LOAD DATA SQL statement. Most options to mysqlimport respond directly to clauses of LOAD DATA syntax
mysqlpump
Let us understand the features of mysqlpump −
Parallel processing of databases, as well as that of objects within databases, thereby helping speed up the dump process.
It provides better control over which databases and database objects (tables, stored programs, user accounts) need to be dumped
Dumping of user accounts as account-management statements (CREATE USER, GRANT) instead of as inserts into the mysql system database
mysqlshow
The mysqlshow client can be used to see what databases exist, their tables, or a table's columns or indexes. It provides a command-line interface for several SQL SHOW statements.
mysqlslap
The mysqlslap utility is a diagnostic program that has designed to emulate client load for a MySQL server and report the timing of every stage. It works as though multiple clients are accessing the server.
Mysql commands are
Working with Database
- CREATE TABLE
- INSERT INTO
- DROP TABLE
- ALTER TABLE
Working with Indexes
- CREATE INDEX
- DROP INDEX
- DROP VIEW
- RENAME TABLE
- CREATE PROCEDURE
- DROP PROCEDURE
- SHOW PRODCEDURE
Working with Triggers
- CREATE TIGGERS
- DROP TIGGERS
- SHOW TIGGERS
Working with Stored Functions
- CREATE FUNCTION
- DROP FUNCTION
- SHOW FUNCTION
Popular queries based on tables
- SELECT
- UPDATE
- DELETE
- WHERE
- REVOKE
- ON
- FROM
- GRANT
- TO
Why Keep MySQL Up to Date?
Manual server maintenance is not a fun task, especially if you’re not very familiar with your webserver’s inner workings. As long as your server and database are working fine, it may be tempting to ignore an outdated piece of software. But there are quite a few reasons why this is a bad idea.
It’s never good to have outdated software on your server. Even the tiniest hole in your security could be a vector for attackers to slip through and take over.
They may even be able to mess with your database. All sorts of important info are stored there, such as your WordPress posts and all other kinds of sensitive bits. You don’t want anyone unwanted to be able to modify that.
Besides that, a new version means new features and general improvements for what’s already there. Even if these extra features don’t affect you, more recent MySQL versions are more secure, better optimized, and faster.
How to Check MySQL Version
It’s crucial to keep MySQL up to date, but you need to know its version before upgrading. Chances are, you’re already using the latest version and don’t need to do anything at all. There are several ways to check; these are just a handful of the easiest ones.
10 Useful mysqladmin Commands for Database Administration
1. Set MySQL Root Password
2. Create a Database
3. Drop Database
4. Check Active Processes
5. Check the Status of the MySQL Server
6. Check MySQL Status Variables
7. Reload MySQL Privileges
8. Connect Remote MySQL Server
9. Run Multiple mysqladmin commands
10. Shutdown MySQL Server
MySQL Workbench
MySQL Workbench Editions
MySQL Workbench is mainly available in three editions, which are given below:
- Community Edition (Open Source, GPL)
- Standard Edition (Commercial)
- Enterprise Edition (Commercial)
Community Edition
The Community Edition is an open-source and freely downloadable version of the most popular database system. It came under the GPL license and is supported by a huge community of developers.
Standard Edition
It is the commercial edition that provides the capability to deliver high-performance and scalable Online Transaction Processing (OLTP) applications. It has made MySQL famous along with industrial-strength, performance, and reliability.
Enterprise Edition
It is the commercial edition that includes a set of advanced features, management tools, and technical support to achieve the highest scalability, security, reliability, and uptime. This edition also reduces the risk, cost, complexity in the development, deployment, and managing MySQL applications.
A lock is a mechanism associated with a table used to restrict the unauthorized access of the data in a table. MySQL allows a client session to acquire a table lock explicitly to cooperate with other sessions to access the table's data. MySQL also allows table locking to prevent it from unauthorized modification into the same table during a specific period.
A session in MySQL can acquire or release locks on the table only for itself. Therefore, one session cannot acquire or release table locks for other sessions. It is to note that we must have a TABLE LOCK and SELECT privileges for table locking.
Table Locking in MySQL is mainly used to solve concurrency problems. It will be used while running a transaction, i.e., first read a value from a table (database) and then write it into the table (database).
two types of locks onto the table, which are:
READ LOCK: This lock allows a user to only read the data from a table.
WRITE LOCK: This lock allows a user to do both reading and writing into a table.
LOCK tables_name[READ/ WRITE];
READ Locks
The following are the features of the READ lock:
- At the same time, MySQL allows multiple sessions to acquire a READ lock for a table. And all other sessions can read the table without acquiring the lock.
- If the session holds the READ lock on a table, they cannot perform a write operation on it. It is because the READ lock can only read data from the table. All other sessions that do not acquire a READ lock are not able to write data into the table without releasing the READ lock. The write operations go into the waiting states until we have not released the READ lock.
- When the session is terminated normally or abnormally, MySQL implicitly releases all types of locks on to the table. This feature is also relevant for the WRITE lock.
Write Locks
The following are the features of a WRITE lock:
- It is the session that holds the lock of a table and can read and write data both from the table.
- It is the only session that accesses the table by holding a lock. And all other sessions cannot access the data of the table until the WRITE lock is released.
Read vs. Write Lock
- Read lock is similar to "shared" locks because multiple threads can acquire it at the same time.
- Write lock is an "exclusive" locks because another thread cannot read it.
- We cannot provide read and write locks both on the table at the same time.
- Read lock has a low priority than Write lock, which ensures that updates are made as soon as possible.
Row-Level Locking
MySQL uses row-level locking for InnoDB tables to support simultaneous write access by multiple sessions, making them suitable for multi-user, highly concurrent, and OLTP applications.
To avoid deadlocks when performing multiple concurrent write operations on a single InnoDB table, acquire necessary locks at the start of the transaction by issuing a SELECT ... FOR UPDATE statement for each group of rows expected to be modified, even if the data change statements come later in the transaction. If transactions modify or lock more than one table, issue the applicable statements in the same order within each transaction. Deadlocks affect performance rather than representing a serious error, because InnoDB automatically detects deadlock conditions by default and rolls back one of the affected transactions.
On high concurrency systems, deadlock detection can cause a slowdown when numerous threads wait for the same lock. At times, it may be more efficient to disable deadlock detection and rely on the innodb_lock_wait_timeout setting for transaction rollback when a deadlock occurs. Deadlock detection can be disabled using the innodb_deadlock_detect configuration option.
Advantages of row-level locking:
- Fewer lock conflicts when different sessions access different rows.
- Fewer changes for rollbacks.
- Possible to lock a single row for a long time.
External locking is used in situations where a single process such as the MySQL server cannot be assumed to be the only process that requires access to tables. Here are some examples: If you run multiple servers that use the same database directory (not recommended), each server must have external locking enabled.
Deadlocks in MySQL occur when two or more transactions mutually hold and request for locks. Deadlocks being present do not always indicate an issue but often are a symptom of some other MySQL or Adobe Commerce issue that has occurred.
Often the application, deployment, or MySQL logs will mention a “deadlock” error or the error “Deadlock found when trying to get lock; try restarting transaction.”
Deadlocks can have multiple causes, but the most common is if you perform any interaction (website/processes/cron jobs/other users/MySQL maintenance/MySQL imports) while performing DML/DDL queries at the same time.
As an example, it is a best practice to avoid a stuck MySQL database import by first putting your site in maintenance mode to avoid getting SQL requests to the database that could cause deadlocks and a stuck database import.
UNIT 3
Table Maintenance Statements
- 13.7.3.1 ANALYZE TABLE Statement
- 13.7.3.2 CHECK TABLE Statement
- 13.7.3.3 CHECKSUM TABLE Statement
- 13.7.3.4 OPTIMIZE TABLE Statement
- 13.7.3.5 REPAIR TABLE Statement
- INFORMATION_SCHEMA Usage Notes
- INFORMATION_SCHEMA is a database within each MySQL instance, the place that stores information about all the other databases that the MySQL server maintains. The INFORMATION_SCHEMA database contains several read-only tables. They are actually views, not base tables, so there are no files associated with them, and you cannot set triggers on them. Also, there is no database directory with that name.
- Although you can select INFORMATION_SCHEMA as the default database with a USE statement, you can only read the contents of tables, not perform INSERT, UPDATE, or DELETE operations on them.
- The MySQL Performance Schema is a feature for monitoring MySQL Server execution at a low level. The Performance Schema has these characteristics:
- The Performance Schema provides a way to inspect internal execution of the server at runtime. It is implemented using the PERFORMANCE_SCHEMA storage engine and the performance_schema database. The Performance Schema focuses primarily on performance data. This differs from INFORMATION_SCHEMA, which serves for inspection of metadata.
- The Performance Schema monitors server events. An “event” is anything the server does that takes time and has been instrumented so that timing information can be collected. In general, an event could be a function call, a wait for the operating system, a stage of an SQL statement execution such as parsing or sorting, or an entire statement or group of statements. Event collection provides access to information about synchronization calls (such as for mutexes) file and table I/O, table locks, and so forth for the server and for several storage engines.
- Performance Schema events are distinct from events written to the server's binary log (which describe data modifications) and Event Scheduler events (which are a type of stored program).
- Performance Schema events are specific to a given instance of the MySQL Server. Performance Schema tables are considered local to the server, and changes to them are not replicated or written to the binary log.
- Current events are available, as well as event histories and summaries. This enables you to determine how many times instrumented activities were performed and how much time they took. Event information is available to show the activities of specific threads, or activity associated with particular objects such as a mutex or file.
- The PERFORMANCE_SCHEMA storage engine collects event data using “instrumentation points” in server source code.
- Collected events are stored in tables in the performance_schema database. These tables can be queried using SELECT statements like other tables.
- Performance Schema configuration can be modified dynamically by updating tables in the performance_schema database through SQL statements. Configuration changes affect data collection immediately.
- Tables in the Performance Schema are in-memory tables that use no persistent on-disk storage. The contents are repopulated beginning at server startup and discarded at server shutdown.
- Monitoring is available on all platforms supported by MySQL.
- Some limitations might apply: The types of timers might vary per platform. Instruments that apply to storage engines might not be implemented for all storage engines. Instrumentation of each third-party engine is the responsibility of the engine maintainer. See also Section 27.20, “Restrictions on Performance Schema”.
- Data collection is implemented by modifying the server source code to add instrumentation. There are no separate threads associated with the Performance Schema, unlike other features such as replication or the Event Scheduler.
- The Performance Schema is intended to provide access to useful information about server execution while having minimal impact on server performance. The implementation follows these design goals:
- Activating the Performance Schema causes no changes in server behavior. For example, it does not cause thread scheduling to change, and it does not cause query execution plans (as shown by EXPLAIN) to change.
- Server monitoring occurs continuously and unobtrusively with very little overhead. Activating the Performance Schema does not make the server unusable.
- The parser is unchanged. There are no new keywords or statements.
- Execution of server code proceeds normally even if the Performance Schema fails internally.
- When there is a choice between performing processing during event collection initially or during event retrieval later, priority is given to making collection faster. This is because collection is ongoing whereas retrieval is on demand and might never happen at all.
- Most Performance Schema tables have indexes, which gives the optimizer access to execution plans other than full table scans. For more information, see Section 8.2.4, “Optimizing Performance Schema Queries”.
- It is easy to add new instrumentation points.
- It is important to back up your databases so that you can recover your data and be up and running again in case problems occur, such as system crashes, hardware failures, or users deleting data by mistake. Backups are also essential as a safeguard before upgrading a MySQL installation, and they can be used to transfer a MySQL installation to another system or to set up replica servers.
- MySQL offers a variety of backup strategies from which you can choose the methods that best suit the requirements for your installation. This chapter discusses several backup and recovery topics with which you should be familiar:
- Types of backups: Logical versus physical, full versus incremental, and so forth.
- Methods for creating backups.
- Recovery methods, including point-in-time recovery.
- Backup scheduling, compression, and encryption.
- Table maintenance, to enable recovery of corrupt tables.
- Instrumentation is versioned. If the instrumentation implementation changes, previously instrumented code continues to work. This benefits developers of third-party plugins because it is not necessary to upgrade each plugin to stay synchronized with the latest Performance Schema changes.
- Physical backups consist of raw copies of the directories and files that store database contents. This type of backup is suitable for large, important databases that need to be recovered quickly when problems occur.
- Logical backups save information represented as logical database structure (CREATE DATABASE, CREATE TABLE statements) and content (INSERT statements or delimited-text files). This type of backup is suitable for smaller amounts of data where you might edit the data values or table structure, or recreate the data on a different machine architecture.
- Snapshot Backups
- Some file system implementations enable “snapshots” to be taken. These provide logical copies of the file system at a given point in time, without requiring a physical copy of the entire file system. (For example, the implementation may use copy-on-write techniques so that only parts of the file system modified after the snapshot time need be copied.) MySQL itself does not provide the capability for taking file system snapshots. It is available through third-party solutions such as Veritas, LVM, or ZFS.
- Online backups take place while the MySQL server is running so that the database information can be obtained from the server. Offline backups take place while the server is stopped. This distinction can also be described as “hot” versus “cold” backups; a “warm” backup is one where the server remains running but locked against modifying data while you access database files externally.
- A local backup is performed on the same host where the MySQL server runs, whereas a remote backup is done from a different host. For some types of backups, the backup can be initiated from a remote host even if the output is written locally on the server. host.
- mysqldump can connect to local or remote servers. For SQL output (CREATE and INSERT statements), local or remote dumps can be done and generate output on the client. For delimited-text output (with the --tab option), data files are created on the server host.
- SELECT ... INTO OUTFILE can be initiated from a local or remote client host, but the output file is created on the server host.
- Physical backup methods typically are initiated locally on the MySQL server host so that the server can be taken offline, although the destination for copied files might be remote.
- A full backup includes all data managed by a MySQL server at a given point in time. An incremental backup consists of the changes made to the data during a given time span (from one point in time to another). MySQL has different ways to perform full backups, such as those described earlier in this section. Incremental backups are made possible by enabling the server's binary log, which the server uses to record data changes.
- Replication enables data from one MySQL database server (known as a source) to be copied to one or more MySQL database servers (known as replicas). Replication is asynchronous by default; replicas do not need to be connected permanently to receive updates from a source. Depending on the configuration, you can replicate all databases, selected databases, or even selected tables within a database.
- Advantages of replication in MySQL include:
- Scale-out solutions - spreading the load among multiple replicas to improve performance. In this environment, all writes and updates must take place on the source server. Reads, however, may take place on one or more replicas. This model can improve the performance of writes (since the source is dedicated to updates), while dramatically increasing read speed across an increasing number of replicas.
- 2. Data security - because the replica can pause the replication process, it is possible to run backup services on the replica without corrupting the corresponding source data.
- 3. Analytics - live data can be created on the source, while the analysis of the information can take place on the replica without affecting the performance of the source.
- 4. Long-distance data distribution - you can use replication to create a local copy of data for a remote site to use, without permanent access to the source.
- MySQL replication is a process that allows data in one or more MySQL database servers, called slaves, to automatically remain in sync with one master MySQL database server. Replication can be very convenient as it enables scalability by spreading out read access to multiple servers, facilitates data backup, and allows data analysis on the slave without accessing the master server. In this shot, we will go over the steps required to replicate data from a master database to a single slave database.
Prerequisites
This shot assumes the following:
- The user has sudo privileges
- MySQL is set up on the machine
- Two servers (the master and the slave) are set and running on two different IP addresses
- REF1
- REF2
- MySQL enables the creation of accounts that permit client users to connect to the server and access data managed by the server. The primary function of the MySQL privilege system is to authenticate a user who connects from a given host and to associate that user with privileges on a database such as SELECT, INSERT, UPDATE, and DELETE. Additional functionality includes the ability to grant privileges for administrative operations.
- To control which users can connect, each account can be assigned authentication credentials such as a password. The user interface to MySQL accounts consists of SQL statements such as CREATE USER, GRANT, and REVOKE.
The MySQL privilege system ensures that all users may perform only the operations permitted to them. As a user, when you connect to a MySQL server, your identity is determined by the host from which you connect and the user name you specify. When you issue requests after connecting, the system grants privileges according to your identity and what you want to do.
- MySQL access control involves two stages when you run a client program that connects to the server:Stage 1: The server accepts or rejects the connection based on your identity and whether you can verify your identity by supplying the correct password.Stage 2: Assuming that you can connect, the server checks each statement you issue to determine whether you have sufficient privileges to perform it. For example, if you try to select rows from a table in a database or drop a table from the database, the server verifies that you have the SELECT privilege for the table or the DROP privilege for the database.
- The privileges granted to a MySQL account determine which operations the account can perform. MySQL privileges differ in the contexts in which they apply and at different levels of operation:Administrative privileges enable users to manage operation of the MySQL server. These privileges are global because they are not specific to a particular database.Database privileges apply to a database and to all objects within it. These privileges can be granted for specific databases, or globally so that they apply to all databases.Privileges for database objects such as tables, indexes, views, and stored routines can be granted for specific objects within a database, for all objects of a given type within a database (for example, all tables in a database), or globally for all objects of a given type in all databases.Privileges also differ in terms of whether they are static (built in to the server) or dynamic (defined at runtime). Whether a privilege is static or dynamic affects its availability to be granted to user accounts and roles. For information about the differences between static and dynamic privileges, see Static Versus Dynamic Privileges.
- RENAME USER StatementRENAME USER old_user TO new_user[, old_user TO new_user] ...The RENAME USER statement renames existing MySQL accounts. An error occurs for old accounts that do not exist or new accounts that already exist.
- MySQL TriggerA trigger in MySQL is a set of SQL statements that reside in a system catalog. It is a special type of stored procedure that is invoked automatically in response to an event. Each trigger is associated with a table, which is activated on any DML statement such as INSERT, UPDATE, or DELETE.A trigger is called a special procedure because it cannot be called directly like a stored procedure. The main difference between the trigger and procedure is that a trigger is called automatically when a data modification event is made against a table. In contrast, a stored procedure must be called explicitly.Generally, triggers are of two types according to the SQL standard: row-level triggers and statement-level triggers.Row-Level Trigger: It is a trigger, which is activated for each row by a triggering statement such as insert, update, or delete. For example, if a table has inserted, updated, or deleted multiple rows, the row trigger is fired automatically for each row affected by the insert, update, or delete statement.Statement-Level Trigger: It is a trigger, which is fired once for each event that occurs on a table regardless of how many rows are inserted, updated, or deleted.
Why we need/use triggers in MySQL?
We need/use triggers in MySQL due to the following features:
- Triggers help us to enforce business rules.
- Triggers help us to validate data even before they are inserted or updated.
- Triggers help us to keep a log of records like maintaining audit trails in tables.
- SQL triggers provide an alternative way to check the integrity of data.
- Triggers provide an alternative way to run the scheduled task.
- Triggers increases the performance of SQL queries because it does not need to compile each time the query is executed.
- Triggers reduce the client-side code that saves time and effort.
- Triggers help us to scale our application across different platforms.
- Triggers are easy to maintain.
Limitations of Using Triggers in MySQL
- MySQL triggers do not allow to use of all validations; they only provide extended validations. For example, we can use the NOT NULL, UNIQUE, CHECK and FOREIGN KEY constraints for simple validations.
- Triggers are invoked and executed invisibly from the client application. Therefore, it isn't easy to troubleshoot what happens in the database layer.
- Triggers may increase the overhead of the database server.
Types of Triggers in MySQL?
We can define the maximum six types of actions or events in the form of triggers:
- Before Insert: It is activated before the insertion of data into the table.
- After Insert: It is activated after the insertion of data into the table.
- Before Update: It is activated before the update of data in the table.
- After Update: It is activated after the update of the data in the table.
- Before Delete: It is activated before the data is removed from the table.
- After Delete: It is activated after the deletion of data from the table.
- MySQL allocates buffers and caches to improve performance of database operations. The default configuration is designed to permit a MySQL server to start on a virtual machine that has approximately 512MB of RAM. You can improve MySQL performance by increasing the values of certain cache and buffer-related system variables. You can also modify the default configuration to run MySQL on systems with limited memory.

Comments
Post a Comment